Artificial Intelligence in Medical Devices - Part 3 Data Management
By Mitch on Friday, 29 August 2025, 13:47 - Processes - Permalink
We continue this series of articles on Artificial Intelligence with the Data Management Process.
This process is required by article 10 of the AI Act, but also from a MDR viewpoint to document the process feeding the AI design process (seen in the previous article part 2) with the right data.
Basically, the right data = the right software (right performance and safety).
The aim of this process is to start from real-world, not sanitized, or unstructured data. At the end, we want to obtain prepared data, ready to use in AI design phases seen in part 2.
You can use this article as a bootstrap to write your own data management process and / or procedure.
Responsibilities
Like any other process we start by describing responsibilities:
For such process used in MDAI, data management but also standards and regulatory compliance need to be managed. An example of allocation of roles may be:
- The chief data scientist or data scientist is in charge of this process.
- The quality and regulatory manager is in charge of the relationships with the ISO 14971 risk management process and the regulatory conformity of the data management process.
- The chief clinical officer is in charge of clinical relevance of data.
- The chief security officer is in charge on data security and privacy.
Process overview
The process described below is inspired from the data management process presented in ISO 5259-1 and collaterals.
The data management process is an iterative process allowing to increase the quality of data at each iteration. It aims to deliver a dataset (processed data in the figure below) to the AI model design process (in green).
The arrow from "Data provisioning" to "Prepared data" symbolizes the data delivery by the data management process to the AI design process. The data management process may deliver data to the AI model design process at early stages, before data review, for dry-runs or when agile methods are used (dotted arrow in the diagram).
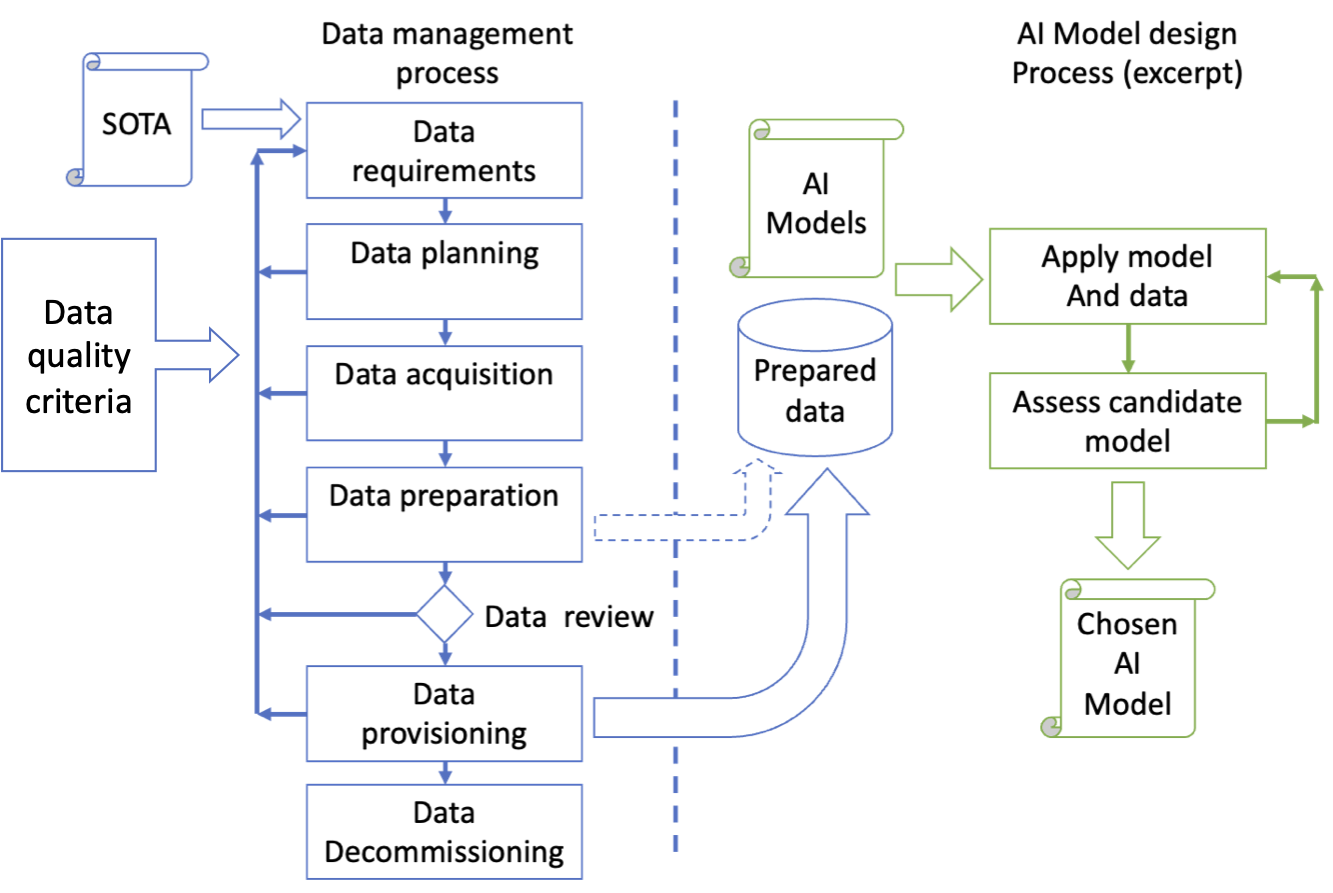
Please refer to part 2 about AI design process for a better explanation of the right part in green on this diagram.
Here are some details on these process steps.
Data requirements
When you develop software, you start with software requirements. When you manage data, you start with data requirements.
Inputs
- Applicable regulations on data,
- AI Act article 10, especially avoiding to have a negative impact on fundamental rights or lead to discrimination prohibited under EU law,
- Other local regulations like GDPR, HIPAA, to name a few,
- Device intended use, and device description,
- High-level product requirement or functional requirements, or system requirements,
- Software requirements.
High-level requirements or software requirements may not be present or fully completed when the data requirements stage starts. These requirements feed the determination of data requirements, and vice-versa. Especially, the feasibility of collecting some data will have an influence on high-level requirements.
Activities
The data requirements stage involves:
- Determining what data are required for the MDAI design, according to the device intended use, target disease, and target population,
- Checking the availability of the data, especially clinical / personal health data, the presence of existing registries, the need of retrospective study or clinical investigation,
- Checking the appropriateness of data, in order to avoid possible biases that are likely to affect the health and safety of persons,
- Checking if data may have a negative impact on regulatory requirements,
- Determining if anonymization or pseudonymization is required (spoiler: yes, most of time),
- Initializing a data quality model with data quality characteristics aiming to represent in a fair and accurate manner the target medical condition and the target population without bias, including sub-groups.
Outputs
- Data Requirement Specification, with:
- Features: Clinical data or other data being considered as having an influence, input of AI model inference,
- Target(s): Clinical or other data being considered as representing the clinical outcome or a contribution to the clinical outcome, output of the AI model inference,
- Traceability to product requirements, functional requirements, system requirements, or software requirements, as appropriate,
- Report on data availability,
- Draft Data Quality Model:
- High-level inclusion and exclusion criteria,
- Number of data items and a justification why this will be sufficient.
For example:
In medical imaging, data requirements may define features as the types of images and sequences needed, and the targets as some reports or some post-processing overlay accompanying the images. The data quality model may be initialized with the number of DICOM studies needed according to some clinical parameters.
In the analysis of medical reports, data requirements may define features as medical data that shall be present in the PDF files extracted from these reports. The data quality model may be initialized with the quality of information present in these reports, matching expected medical data.
Data planning
Once you have your data requirements, you can plan:
- How you’ll get data,
- How data will be structured.
Inputs
- Data Requirement Specification.
Activities
The data planning stage ensures that:
- The data to be used meet the requirements of the data requirements stage,
- More generally, the clinical goals of the AI model design project will be met.
This stage involves:
- Designing the data architecture (e.g: design data so that the architecture can match the clinical parameters required to represent the target disease and target population),
- Defining how data will be used:
- Dataset for training or tuning,
- Dataset for AI validation,
- Dataset for AI test,
- Dataset for device validation (if different from AI test),
- Other dataset, if any….
- Defining the data acquisition plan:
- Either acquiring anonymized data, or planning anonymization or pseudonymization,
- Obtaining data from off-the-shelf registries or databases (secondary use of clinical data) maintained by third-parties,
- Or performing a retrospective clinical study (secondary use of clinical data),
- Or using clinical data from a register built in PMCF of another manufacturer’s device (secondary use of clinical data),
- Or performing a clinical investigation.
- Documenting the data retention time, location and protection measures.
- Defining a data Quality Model, describing the expected quality measures used to ensure:
- The presence of clinical and technical inclusion and exclusion criteria using relevant attributes,
- A satisfying representation (in terms of coverage, accuracy etc.) of clinical data amongst the target disease and target population,
- Compliance to regulatory requirements on data, the absence of bias, including in subgroups, and the absence of impact on safety, performance, and human rights.
- A discussion on the influence of the type and location of planned data acquisition has on the data.
Outputs
- Data architecture, such as tabular format, or other format,
- Data acquisition plan,
- Data Quality Model.
For example:
In medical imaging, data architecture may define precisely the expected structure of DICOM files, the tags needed, the content of overlays, the content of DICOM structured reports. The data quality model may define the voxel size, the slice thickness, the presence of mandatory tags…
In the analysis of medical reports, data architecture may be a simple tabular format, containing information extracted from pdf files, the range of data found in columns, enums representing possible values in some columns. The data quality model may be defined from the presence or absence or relevance of information present in medical reports.
The influence of the type and location of planned data acquisition may be based on the characteristics of the local population where data will be acquired.
Data acquisition
Inputs
- Data architecture,
- Data acquisition plan,
- Data Quality Model.
Activity
Data acquisition is performed according to the data acquisition plan (no surprise). Anonymization or pseudonymization is also performed according to the plan.
Collected datasets are tested against a subset of data quality requirements, if some of these requirements can be tested prior to data preparation.
Outputs
- Acquired data,
- Data acquisition records, according to data acquisition plan,
- Data quality requirements preliminary testing report, including the discussion on the influence of the type and location of data acquisition had on the data.
Data preparation
Data preparation aims to prepare (groom) data to obtain datasets that can be used in the AI model design project.
Inputs
- Acquired data
Activities
Various preparation techniques are used to prepare data. Not all preparation techniques may be used for a given project.
One or more Data Preparation Reports log operations performed, and if required, rationale for such operations, and results.
Outputs
- Prepared data
- Data preparation report
Some commonly used preparation techniques are described below.
Aggregation
Aggregation consists in merging one or more datasets in a single dataset and removing duplicates. Assembling research cohorts can be seen as data aggregation.
The concept of duplicate may not be data items strictly containing the same values. In this case, the removal of duplicates may require a validation by a person with clinical background or other relevant background.
Sampling
Sampling consists in randomly selecting data items in very large datasets, to obtain a dataset of size manageable by the AI model design project team.
The sampling method may be present in a statistical analysis plan and/or may require a validation by a person with a statistical background or a clinical background.
For example:
- For diseases with a low incidence, an over-sampling of positive cases may be required to have more positive cases in the dataset, and better train an AI model on these cases,
- For data used for clinical validation, the sampling method may require a review by persons with a clinical background to confirm the right representation of the target population.
Imputation
Imputations consist in:
- Replacing a missing value by a default value in a data item, or
- Deleting the data item.
The choice of the default value depends on the nature of the data. In some cases, it may not be possible to set a default value. Then, the data item shall be deleted if the missing value is relevant (see features selection) for the AI model training.
The choice of default values may require a validation by a person with clinical background.
Cleaning
Cleaning consists in several possible operations, like:
- Shifting values, e.g.: from [10..19] to [20..29],
- Replacing values by others e.g. {“Woman”, “Teen”, “Baby”} by {“Adult”, “Pediatric”, “Pediatric”}
The choice of the cleaning operations depends on the nature of the data. The choice of operations to be performed may require a validation by a person with clinical background.
Outliers’ treatment
This step consists in detecting outliers and treating them (deleting, replacing).
Detecting outliers may require methods such as:
- Visualization, e.g.: with boxplot diagram, scatter diagram,
- Basic math treatment on data (min, max, threshold, average…),
- Splitting data in quartiles, and keeping data within a min and max thresholds,
- Advanced statistical analysis on data.
The choice of the operations used to detect outliers depends on the nature of the data. The choice of operations to be performed may require a validation by a person with clinical background and/or statistical background.
Features Creation
This step consists in creating new features that can capture information in data more efficiently than the original features.
The decision to create features depends on the nature of the data. The operations to be performed may require a validation by a person with clinical background.
Impact analysis: the new features may require the update of the data requirements and data acquisition plan.
Example:
- For time-series data, a new feature may be the average of one attribute over a given period of time.
Labelling and annotation
This step consists in generating meta-data representing information relevant for the AI model training.
Labelling and annotation can require methods such as:
- Manual annotation by qualified personnel,
- Automated annotation by on-purpose tool (in-house developed or off-the-shelf).
The choice of the operations used to generate meta-data depends on the nature of data and meta-data. The choice of operations to be performed may require a validation by a person with clinical background and/or statistical background.
Difference between annotation and labelling:
Annotation is a general term; it can be done on any data. E.g.:
- Automated segmentation of images or automated placement of bounding boxes,
- Adding contextual information like patient information or device used to acquire data.
Labelling is usually performed on dataset in the case of supervised training, associated with target variables:
- E.g.: Classification of images: yes or no (for binary classification).
Annotation and labelling operations shall be performed by qualified persons. E.g.: persons with clinical background or other relevant background on the device, the intended use, the technology.
If data annotation is automated (most of cases) the data annotation tool may require a validation according to the QMS SW validation procedure.
Example:
- Manual generation: Radiologists annotate DICOM files with regions of interest.
- Automated generation: An in-house trained LLM is used to review physicians’ reports (unstructured data), to automatically annotate data with a categorized clinical outcome (structured data).
Features selection
Features selection consists in finding which data are the most relevant in the data model.
E.g.: for data represented in tabular format, which columns are relevant or useful in the table, to train the AI model.
Conversely, features selection can be also performed by finding which data have little or not effect on the AI model.
Features selection usually consists in the following operations:
- Deleting data, when variance is below a given threshold,
- Selecting data with best independence, using a statistical test like chi square test,
- When the model allows to get parameters, pretrain a model with the dataset, e.g.: a linear model like a Stochastic Gradient Descent Classifier.
Data dependence may be represented with heatmaps.
Note 1: Since feature selection aims to enhance model performance, results are usually an increase in model performance.
Note 2: If data is deleted or put apart, it may be necessary to remove this data from the data requirements and data acquisition plan.
Augmentation
Data augmentation consists in adding synthetic data to a dataset in order to better train an AI model.
The augmentation method may require a validation by a person with a clinical background.
For example:
- An AI model is intended to be used with photos taken by patients with their mobile phone. Data augmentation may be necessary to generate photos with poor quality (low contrast, wrong exposition, various angles) to better train the AI model.
If data augmentation is automated (most of cases) the data augmentation tool may require a validation according to the QMS SW validation procedure. Tip: such tool is usually a low-risk QMS software.
Encoding
Encoding consists in operations to convert data not represented by a number to data represented by a number:
- Converting labels to numbers, e.g. {“Adult”, “Pediatric”} to {0, 1}
- Converting dates to numbers, e.g. the number of days since 1970-01-01.
Normalization
Normalization consists in setting all data in range 0…1 or -1…1. It allows to ease computations during training.
Data Normalization usually consists in the following operations:
- Centering data on their average and dividing data by their maximum value in the dataset, e.g.: blood pressure values from 5…18 to 0.28…1,
- Centering data on zero and dividing data by standard deviation, e.g.: blood pressure values from 5…18 to -1…1,
- Splitting data in 4 quartiles and selecting quartiles around the median.
Data normalization may be represented with distribution curves before and after normalization.
Train and AI validation Split
Train and AI validation dataset, split the dataset is to parts. For example:
- 80% for training,
- 20% for AI validation.
Document as appropriate the splitting operation and ratio, if specific operations were performed or if unexpected events happened.
Data review
This step is a formal review of datasets prior to their provisioning and use in the AI model design project. This step may be planned for each dataset at distinct milestones or design reviews.
For example: the data review of the AI test dataset will usually happen later than the data review of the training / AI validation dataset.
This review shall ensure that:
- Data acquisition and data preparation steps have been performed according to planned provisions,
- Datasets meet the data quality requirements, especially inclusion and exclusion criteria,
- Datasets meet the regulatory requirements,
- If limitations exist, limitations on datasets shall not have an impact on safety, performance and regulatory requirements, nor introduce a bias.
Data provisioning
Data provisioning consists in applying the prepared dataset to the AI model being design. The dataset shall be:
- Identified,
- Versioned,
- Put into configuration management,
- Accompanied with descriptive statistics summary,
- Provided with metadata allowing the verification of dataset integrity. E.g.: SHA checksum
The data quality issues detected when applying the dataset to the AI model are recorded in the data preparation report. They can be used as feedback to update the data requirements, planning, acquisition and processing.
Remark: augmented data may not be put into configuration. Rationale for not putting into configuration augmented data is usually based on the random generation nature of these data.
Data decommissioning
Input
- All datasets
Activities
Data decommissioning consists in:
- Either destroying data in a safe manner,
- Or archiving data for a retention time defined according to regulatory requirements (with planed destruction)
- Or transferring data to another department, entity, organization,
- Or returning data to the data holder.
Output:
Data decommissioning report
Relationships with risk management processes
We end this process description with its link with the risk management process.
More precisely, wrong data is a hazardous phenomenon from a risk management perspective. The data management process aims to deliver the right data. Thus, it is a kind of risk control measure at QMS process level. Not product level.
Of course, risks shall be monitored throughout the data management process. This is essentially done by ensuring a good communication with the risk management team, with participation of risk management team representative in:
- The review of data requirement specification,
- The review of and data acquisition plan,
- The data review itself.
Risk management is the subject of the next article. We'll see how to manage risks specific to MDAI.